浏览器工作原理
第一部分 导航
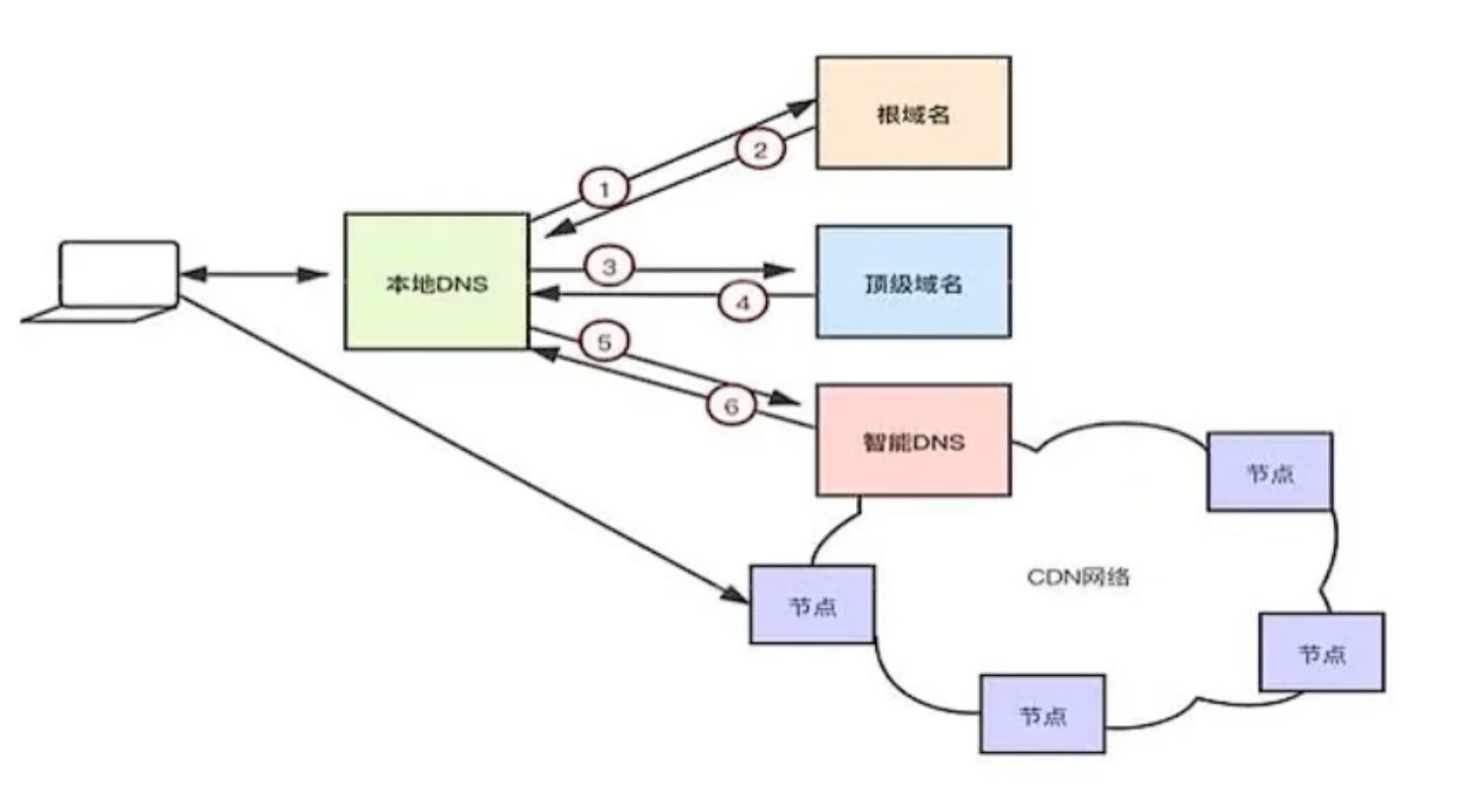
1.DNS域名解析(应用层实现)
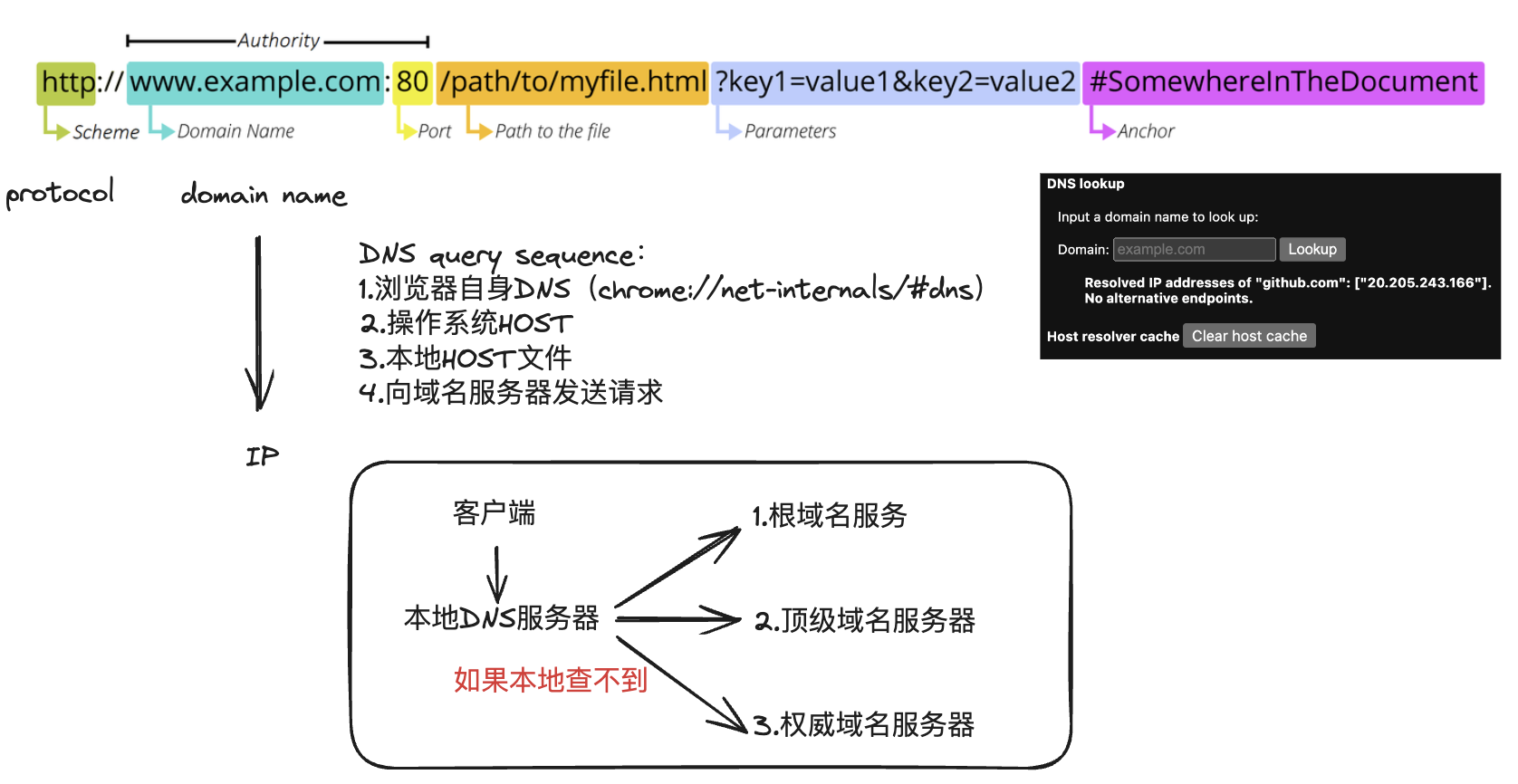
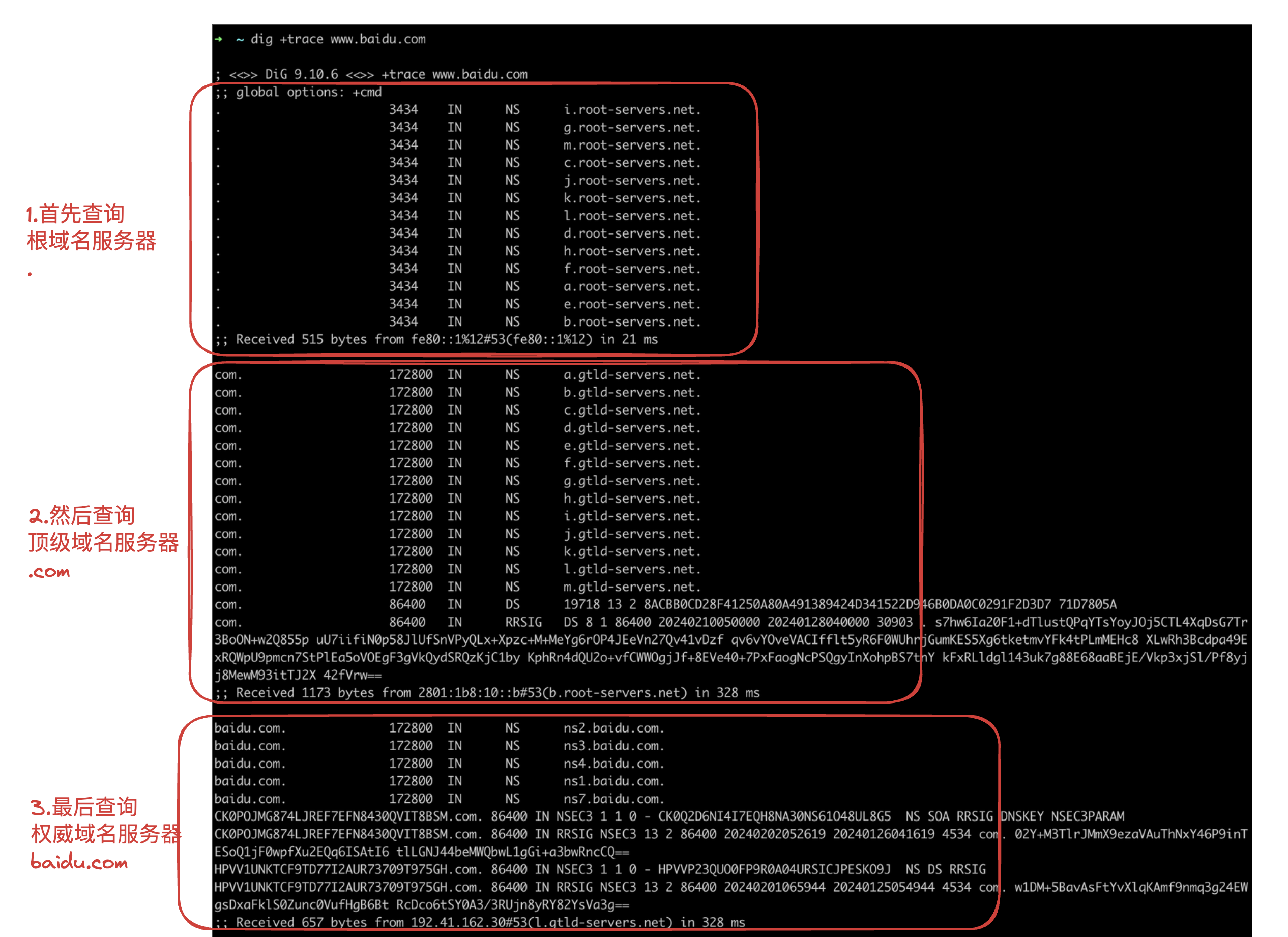
注意,如果配置过CDN,DNS解析过程会发生变化,第三步不再是查找权威域名服务器,而是智能DNS
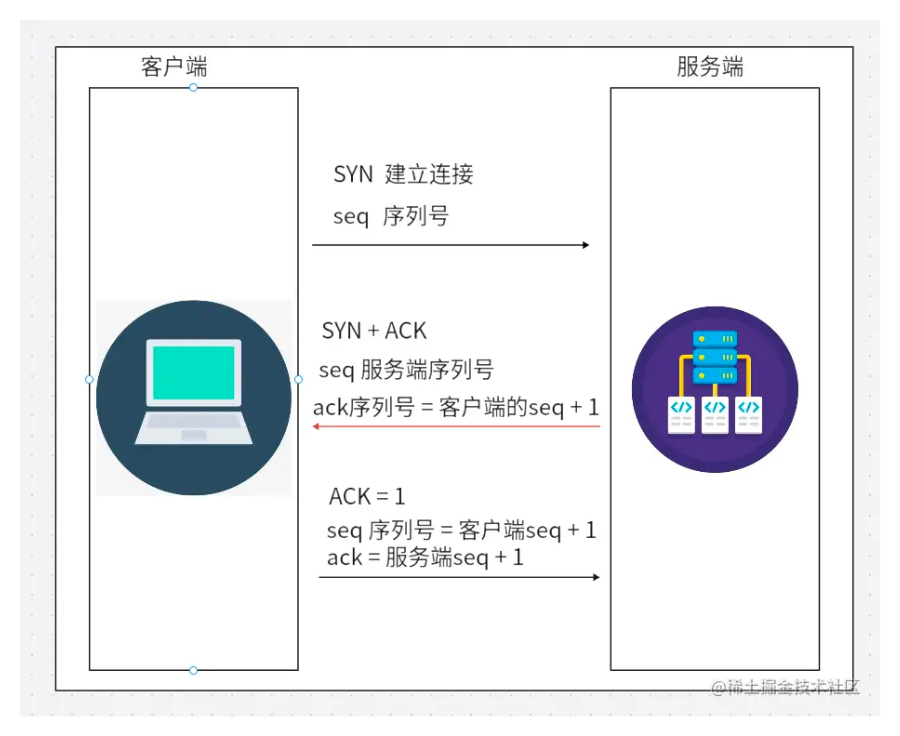
2.传输层三次握手建立TCP连接
3.TLS协商
对于HTTPS建立的安全连接,还需要额外进行一次TLS negotiate
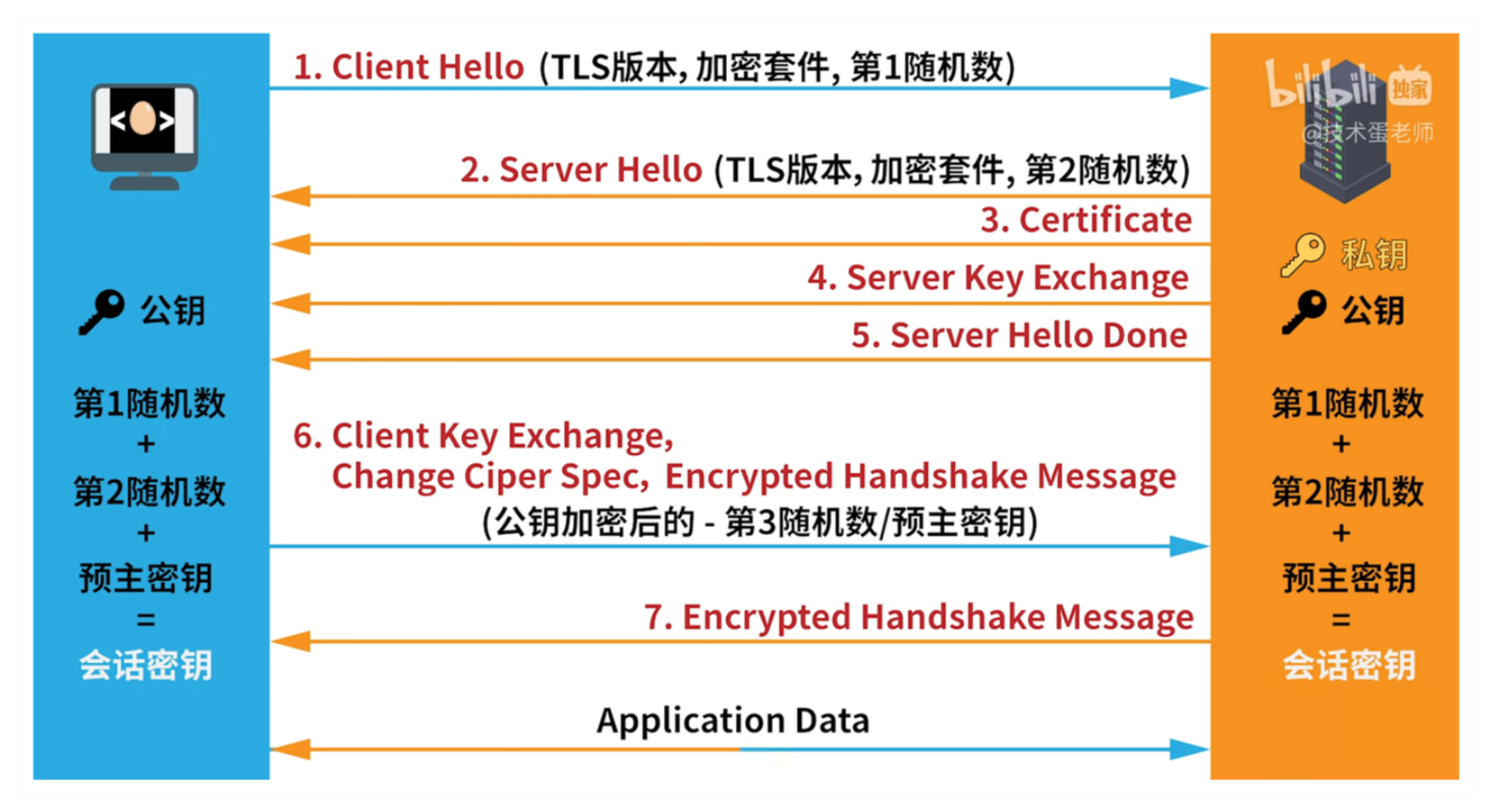
客户端hello。浏览器向服务端发送一条消息,包含TLS版本号、
加密套件和一串在浏览器随机生成的字节,简记为第1随机数或客户端随机数服务端hello。服务端向浏览器发送一条消息,包含TLS版本号、
加密套件和一串在服务端随机生成的字节,简记为第2随机数或服务端随机数服务端发送SSL证书(一般是CA认证颁发、安装到服务器上的)
服务端交换公钥
服务端消息完毕
浏览器向CA合适认证服务器发送的SSL证书。
之后在浏览器生成一串随机字节,简记为第三随机数或预主密钥,
根据客户端随机数、服务端随机数和预主密钥生成会话密钥,
把预主密钥通过公钥加密后发给服务端,发送消息可以开始对话服务器用私钥解密得到预主密钥,
根据客户端随机数、服务端随机数和预主密钥生成会话密钥,发送消息可以开始对话浏览器和服务器使用会话密钥进行对称加密传输数据
preconnect dns-prefetch
浏览器在空闲时间预先进行:
dns-prefetch: DNS lookuppreconnect: DNS lookup + TCP handshake + TLS negotiation
第二部分 资源请求与加载
1.应用层发送HTTP请求
请求主要分为三部分:method headers body
method方法除了简单的get post之外还有遵从restful规范的put delete patch等方法,需要注意的是options,是发送preflight
预检请求的方法,如果一个HTTP Request不存从以下两点安全性要求:
安全的方法:GET POST HEAD
安全的headers:仅允许自定义下列 header:
- Accept
- Accept- Language
- Content-Language
- Content-Type 的值为 application/x-www-form-urlencoded,multipart/form-data 或 text/plain。
浏览器基于安全性考虑就会发送preflight(预检请求,方法不是POST/GET等,而是OPTIONS),通过之后才会发送真正的请求
2.HTTP响应
状态码、响应头、响应体
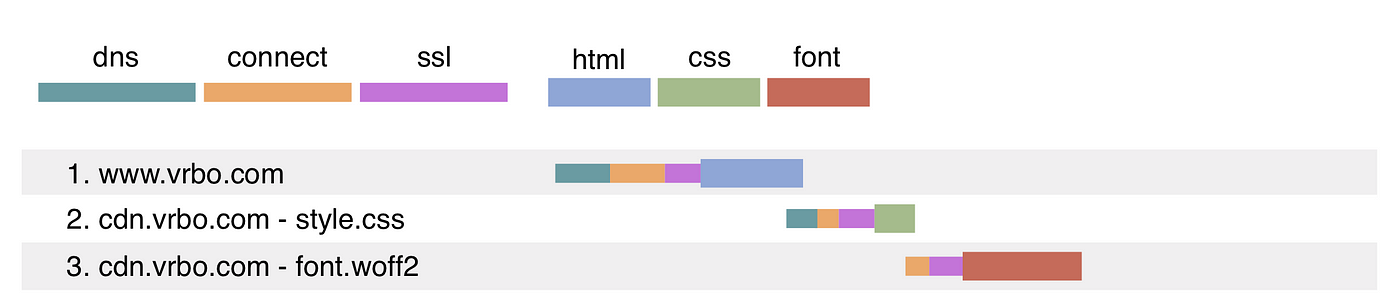
3.下载初始页面资源
现代应用往往采取前后端分离的模式、CSR渲染方式,因此初始资源往往是简单的html和大量css、js脚本以及静态资源
对于SSR,初始资源是已经装配可以直接呈现的html页面、少量css和js脚本、静态资源
4.浏览器的强缓存和协商缓存
强缓存
第一次成功发送请求并且成功获取响应之后,如果后台设置了强缓存,会强制浏览器将服务端提供的资源缓存在硬盘(disk cache)或者内存(memory cache)中。
下次刷新浏览器发送同样的请求,如果没有超出浏览器缓存的时间限制,浏览器会直接返回请求内容,不会再通知服务端、请求服务端。
如果超出了max-age或expires规定的时间,服务器强缓存的资源就过期了。
max-age的优先级高于expires,前者是HTTP1.1支持,后者HTTP1.0支持。

协商缓存
当服务端发现资源的最后修改时间Last-Modified和If-Modified-Since值相等,代表资源从该时间之后从未改变过,返回304状态码和空响应体,浏览器拿到后知道原本可能过期的强缓存内容还可以继续使用。
如果值不相等,说明资源改变了,就会返回200状态码,响应体内为最新资源
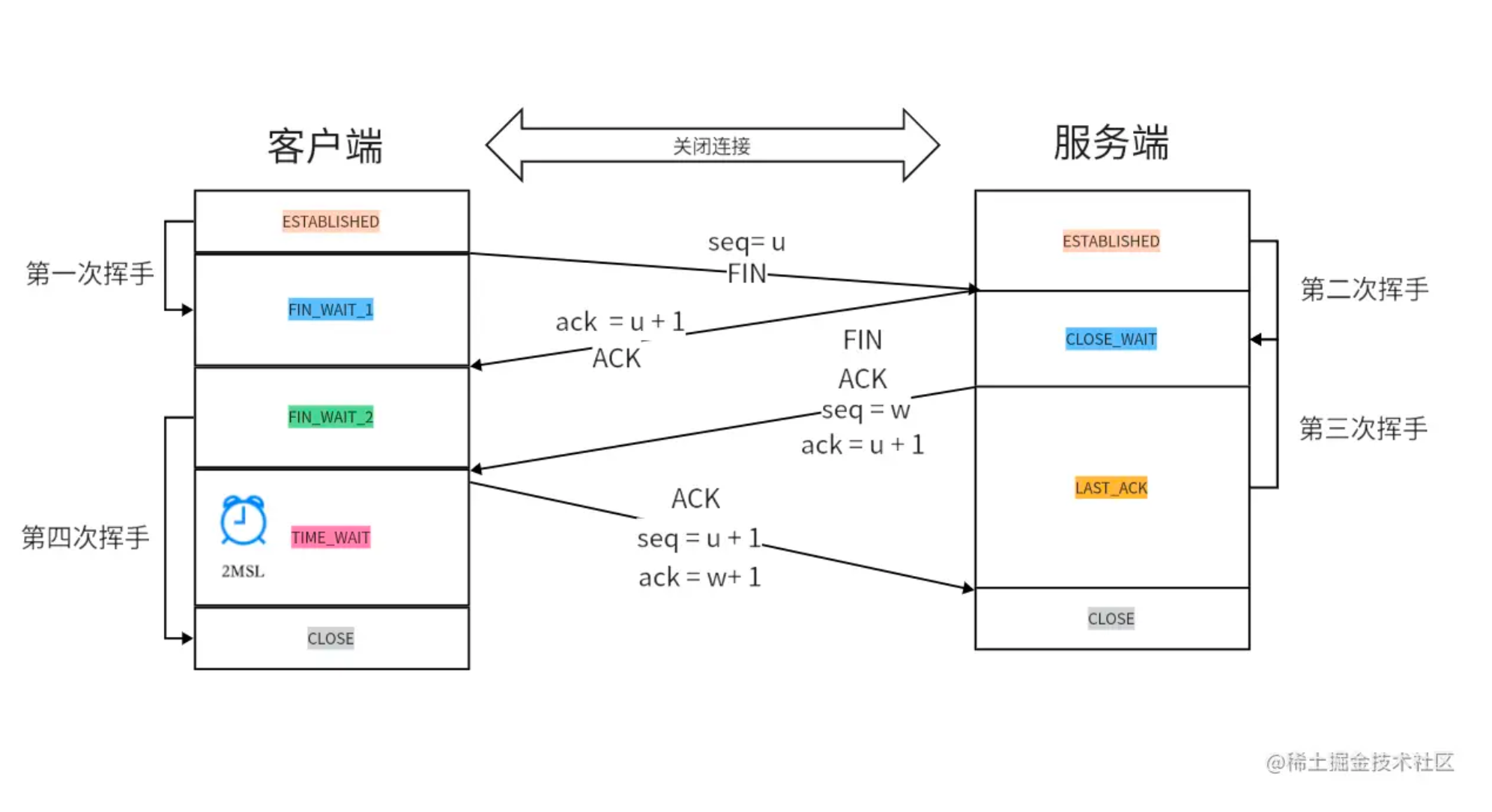
5.四次挥手断开TCP连接
第三部分 HTML解析
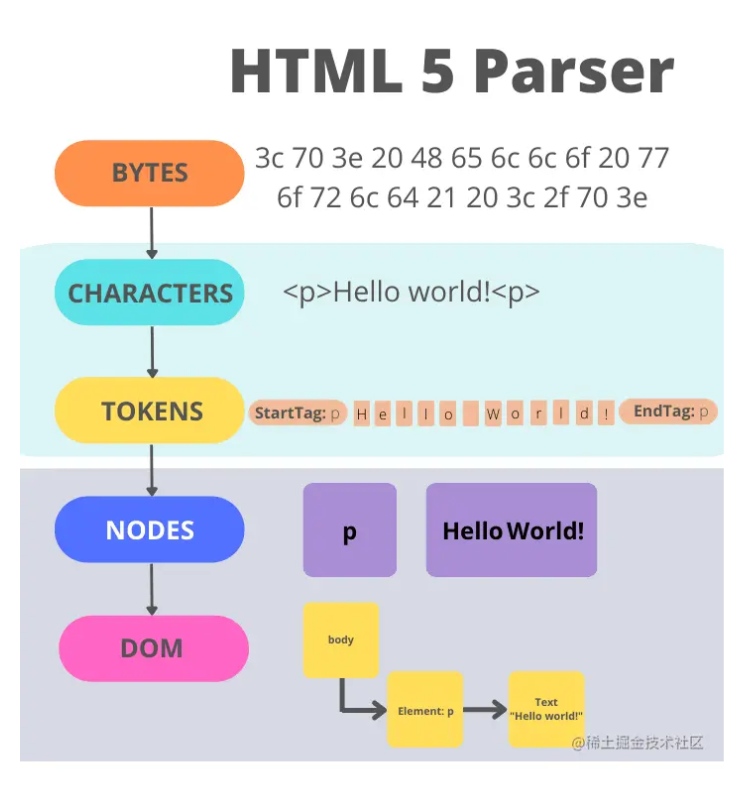
使用HTML Parser进行:
- 将GET请求获取的字节流解码得到字符,
- 将字符character转换成标签token
- 将标签token转化为Node
- 根据token组装DOM树
- 解析器从上到下逐行解析执行
当遇到阻塞资源如css样式表、js、图片、视频等,阻塞解析
当遇到非阻塞资源,如async、defer的js文件时,不阻塞
注意:DOM树也是AST的一种
preload prefetch async defer
preload:立即加载,不立即执行
prefetch:空闲时加载,不立即执行
async:异步加载
defer:延时加载
第四部分 CSS解析
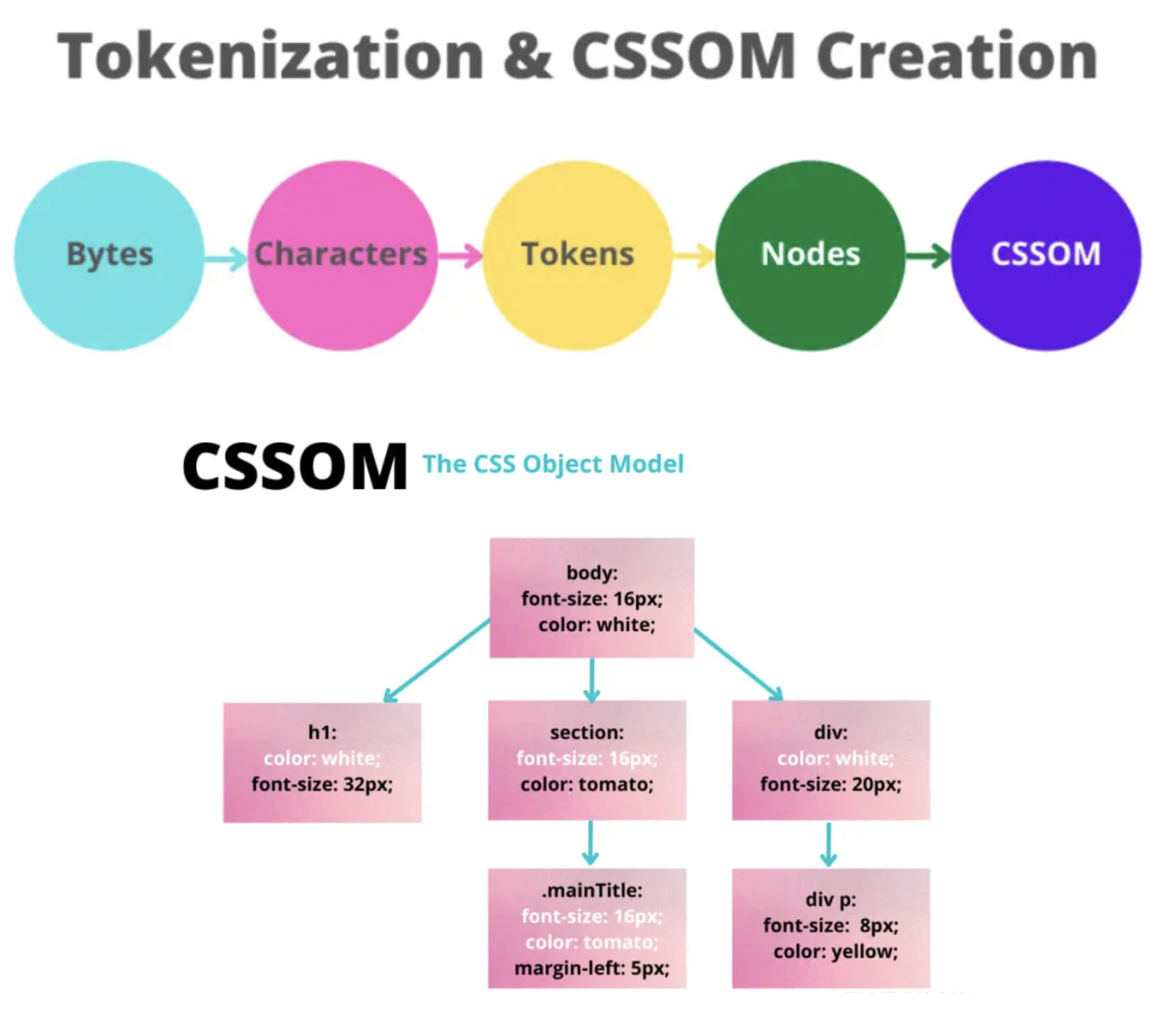
过程类似HTML,但是CSS selector是从右向左读的
section p { color: blue; },
浏览器将首先查找页面上的所有 p 标签,
然后它会查看这些 p 标签中是否有一个 section 标签作为父标签。
如果查找能够命中,它将应用这个 CSS 规则
第五部分 javascript执行
浏览器内核与js引擎
浏览器内核:最初内核的概念包括渲染引擎和js引擎,目前直接称渲染引擎为内核,js引擎独立
渲染引擎:rendering engineer,主要功能是解析HTML/CSS渲染页面
js引擎:专门处理javascript脚本的virtual machine、解释器
过程
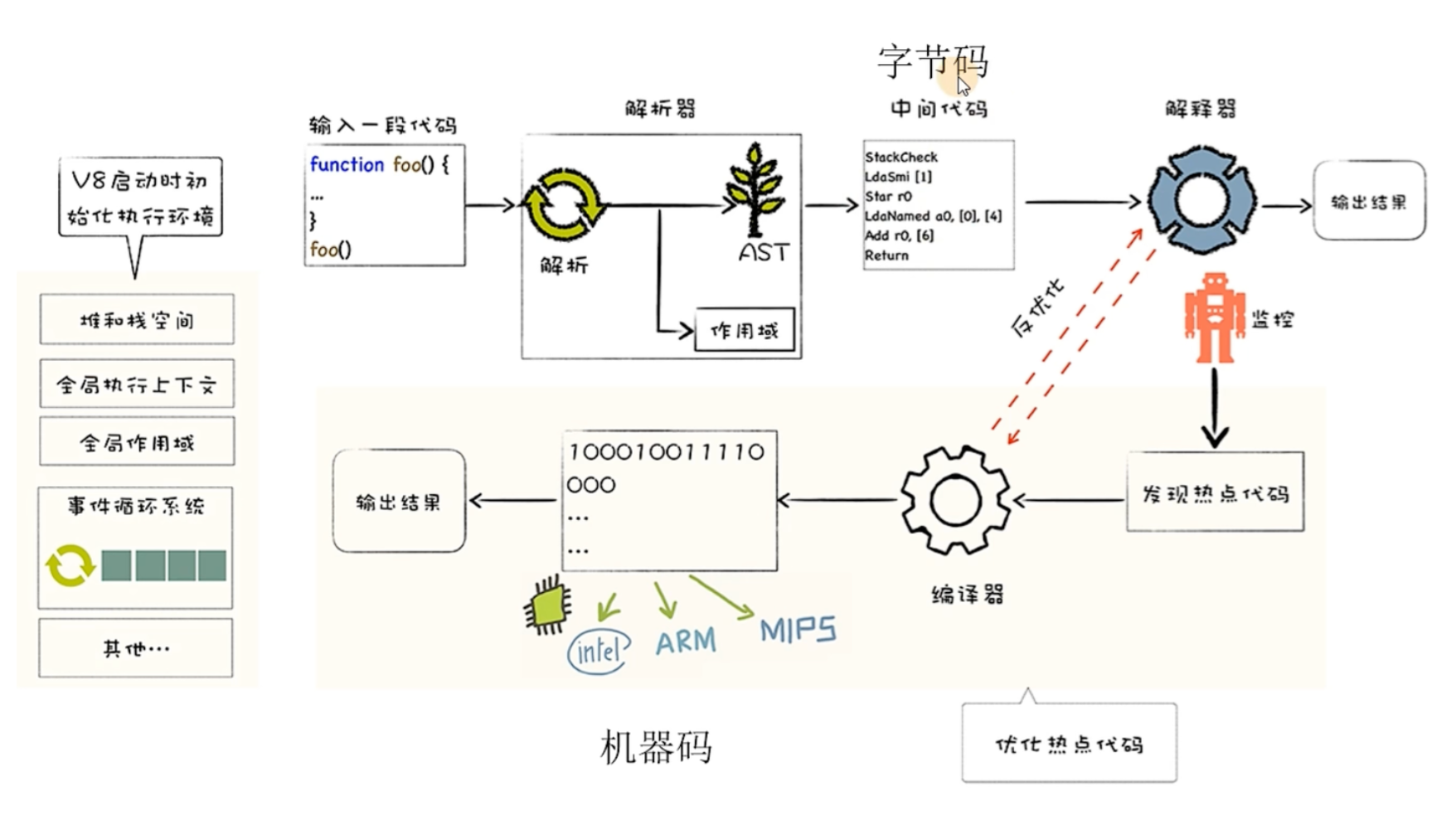
compiler、interpreter、Just-In-Time compiler
V8解释器基于JIT(Justin Runtime)实现
- 编译器:编译代码
- 解释器:运行代码
- JIT 编译器【即时编译】:在运行代码时进行编译(将源代码编译成针对当前运行环境下的字节码,这是一种优化)
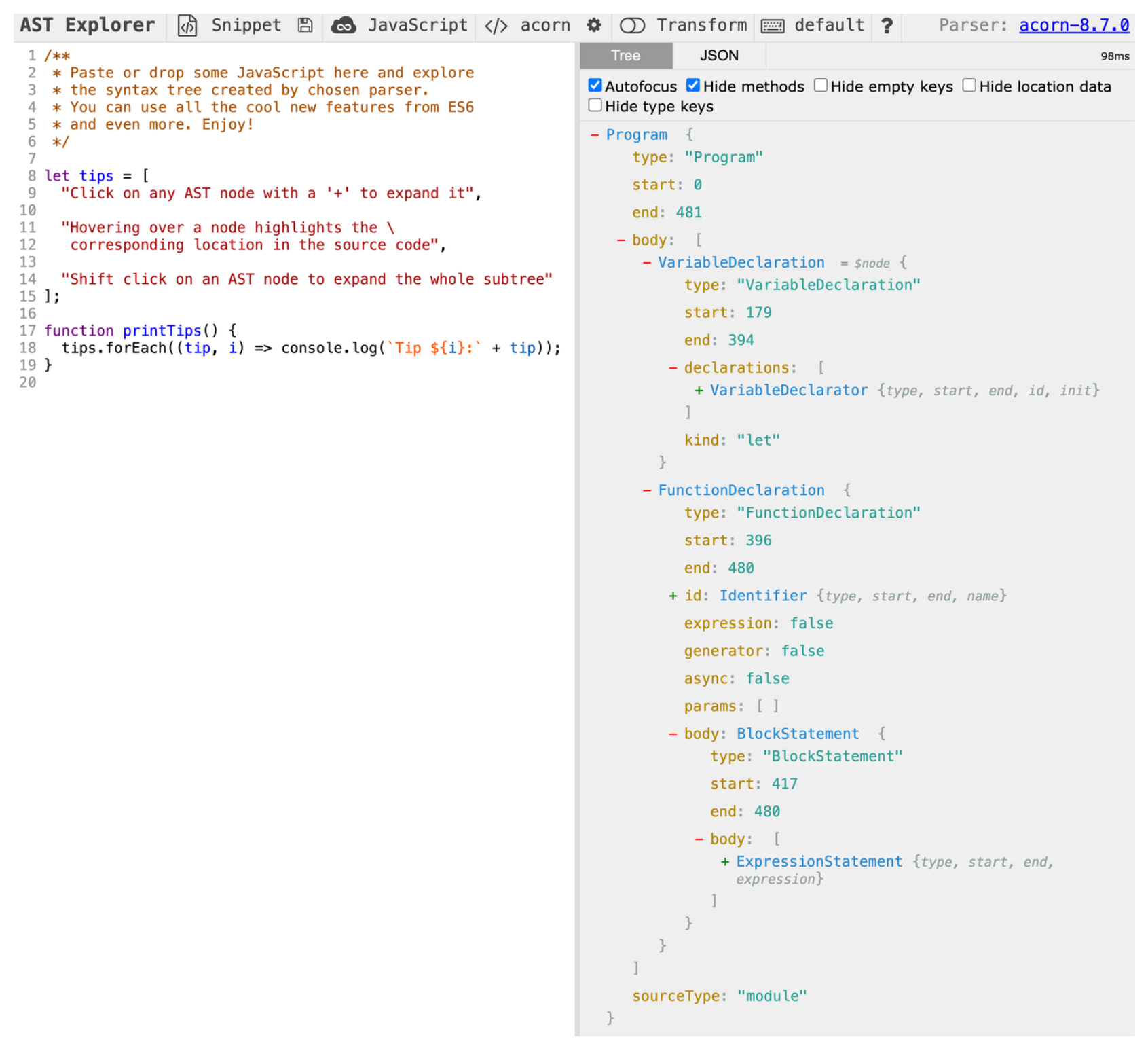
为什么不把js代码直接编译成机器码,而是有中间的字节码?
因为浏览器的运行环境可能不同,比如操作系统、CPU硬件资源可能不同,为了实现跨平台的兼容通用,JS代码统一解析成字节码,字节码的解释器和编译器适配各个平台,最终编译成机器码,由浏览器调度硬件资源执行指令
第六部分 创建可访问(无障碍)树
可访问性树是使用 DOM 构建的,稍后辅助设备将使用它来解析和解释我们正在访问的网页的内容。
ACT 就像 DOM 的语义版本,每次 DOM 更新时它都会更新。
每个需要暴露给辅助技术的 DOM 元素都会在 ACT 中有一个对应节点。
在未构建 ACT 之前,屏幕阅读器无法访问内容。
第七部分 渲染
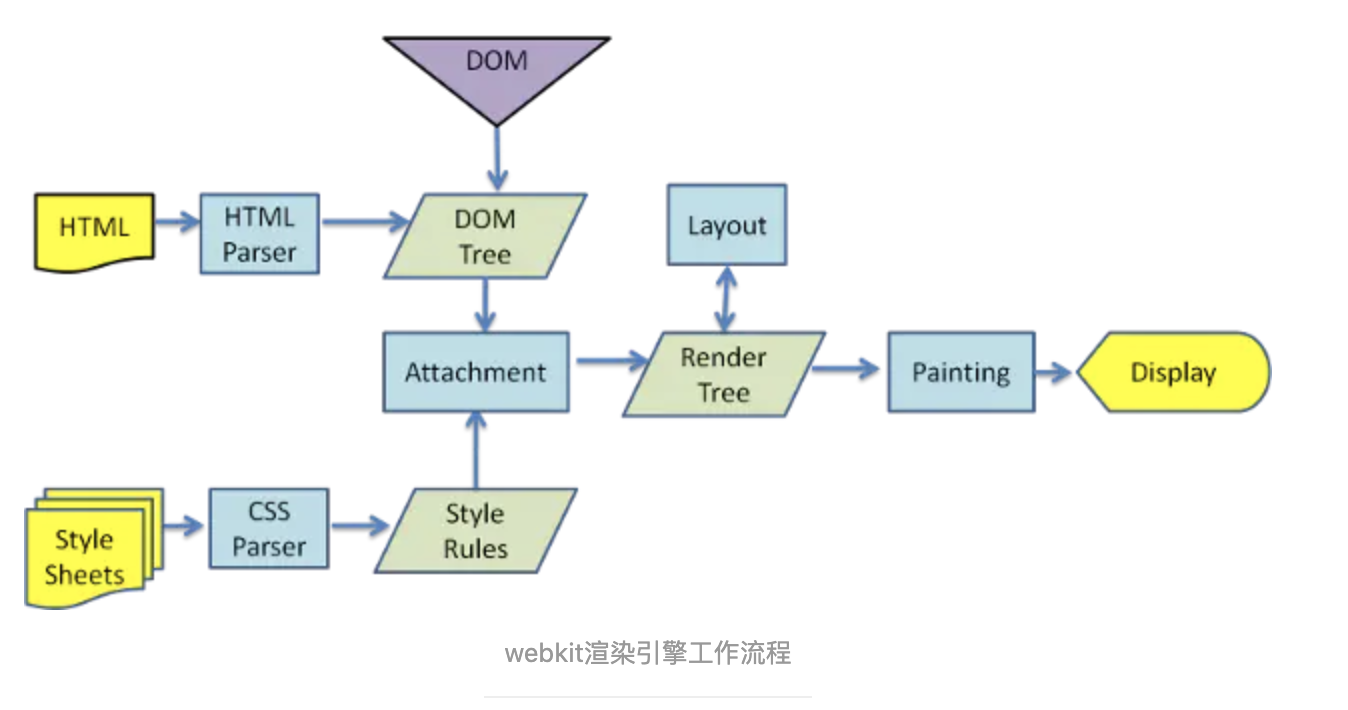
1.关联 attachment
将DOM和CSSOM组合成渲染树render tree
每个DOM节点都有attach方法,接收样式,返回一个render对象,这些render对象最终会被构建成一棵render树
2.布局 layout —— 回流/重排 reflow
布局:计算渲染树上每个节点的尺寸和几何位置
回流:当render tree中部分或全部元素的尺寸、结构或者某些属性发生改变时,浏览器重新渲染部分或全部文档的过程。
会导致回流的操作:
- 页面首次渲染
- 浏览器窗口大小改变
- 元素尺寸或位置改变
- 元素字体大小改变
- DOM元素增删
- 激活CSS伪类
一些常用且会导致回流的属性和方法:
- clientWidth clientHeight clientTop clientLeft
- offsetWdith offsetHeight offsetTop offsetLeft
- scrollWidth scrollHeight scrollTop scrollLeft
- getBoundingClientRect
3.绘制 paint —— 重绘 repaint
绘制:将渲染树上的各个节点绘制到屏幕上
重绘:节点颜色发生变化后重新绘制
4.合成展示 display
当文档的各个部分以不同的层绘制、相互重叠时会进行合成,确保以正确的顺序绘制显示在屏幕上
总结
总共分为三个部分:
- 导航
- 资源加载
- 页面解析与渲染